January 2 2022
Leveraging Forever-Incremental Backup Technology for Customer-Centric Data Protection

Let’s say you have a computing environment, and you need to protect its contents over time. You need a backup: a versioned snapshot of the systems for point-in-time restores. Any backup solution will be optimized for certain criteria–simplicity, completeness, flexibility, etc–but each one needs to perform backups. Let’s walk through the three different types:
- Full Backup: This is a complete point-in-time snapshot of a volume. It takes up the most space.
- Differential Backup: This is a backup that only depends on one full backup. If you have two differential backups based on one full backup, each differential backup only depends on that one full backup and thus take up more space.
- Incremental Backup: This is a backup that depends on a full backup and a number of incremental backups. This is the smallest backup format you can have because it only takes up as much space as necessary to preserve point-in-time restores for each recovery point.
Retrospect Backup’s core engine uses forever-incremental file-based backup technology to protect individual files and folders as well as full systems. Forever-incremental backup allows you to only back up file and system changes since the previous backup, minimizing backup time and storage costs.
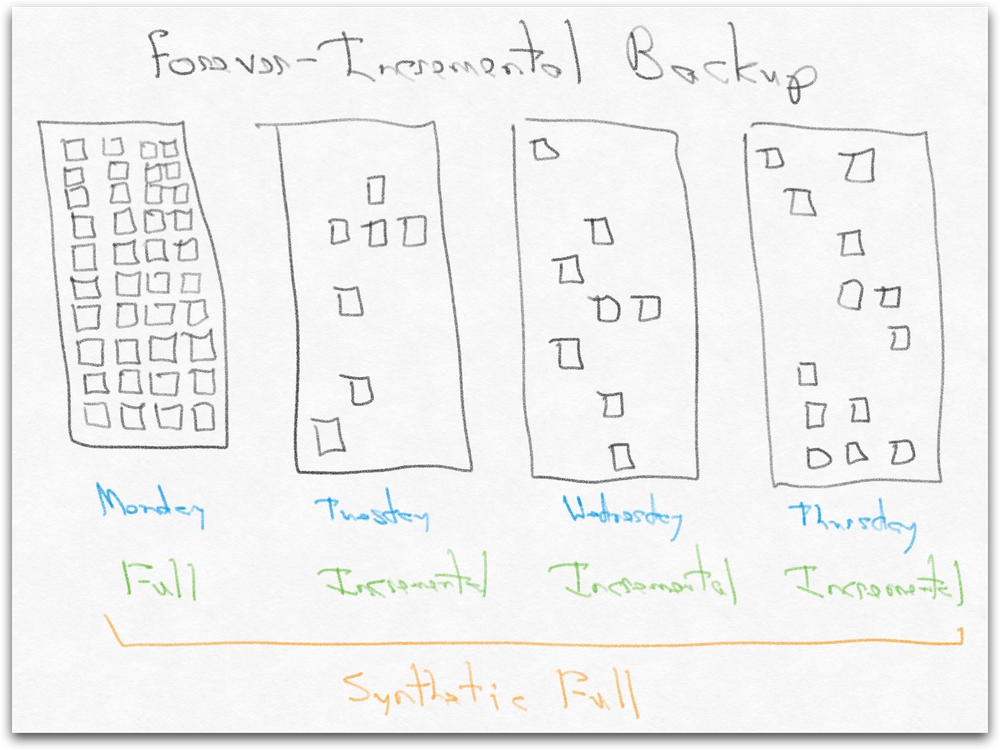
When you restore, Retrospect will combine these incremental backups into a synthetic full backup, giving you a point-in-time restore for a set of files or a full system.
This customer-centric approach allows businesses to leverage the speed of file-based recovery, restoring a file to the Desktop or to the original location. IT administrators can even restore an entire folder structure based on settings like “Do not replace newer files”, allowing IT to recover a large folder structure in place on the affected server or endpoint without determining whether files have been touched more recently than the backup.
Retrospect Backup’s goal is to protect your entire environment the way you need it, giving you as much flexibility as possible.
Workflow Components
Retrospect Backup leverages a number of components to optimize its forever-incremental file-based backup workflow:
- System State: Retrospect includes system state, application state, disk layout, and boot information to support disaster recovery scenarios. To capture an accurate backup of a Windows system, Retrospect utilizes Windows Volume Shadow Copy Service (VSS) to snapshot the system, so that with the other information, it can perform a full disaster recovery (DR), also bare-metal recovery (BMR).
- Filtering: Businesses need to be able to include or exclude files based on how critical they are to the business. Music and movies can be excluded while preserving the ability to perform a bare-metal recovery.
- Destinations: Retrospect supports a wide range of destinations–disk, NAS, tape, and cloud–and backups can be transferred between different storage locations.
- Scheduling: Organizations have their own unique business flow, and Retrospect allows them to schedule their data protection strategies based on their business needs.
- Scripts: Retrospect supports different types of actions on data, including backup, replication, archive, and transfers with support for block-level incremental backup (BLIB) and file-level deduplication for backup scenarios. Transfers allow customers to make a copy of a backup in another storage destination, with support for different destination types, filtering, and scheduling. Customers can make one backup of a source and then move it multiple places without touching the source again. Customers can even enable automatic backup healing by using a “Verify” script to auto-heal their backups. If any issues are found, Retrospect will back up the affected files in the next backup. It’s a flexible approach that you can apply to each backup set on your own schedule to detect and fix integrity issues automatically.
- ProactiveAI: Retrospect’s unique ProactiveAI policy-based scheduling enables businesses to intelligently protect their infrastructure based on policy window. Endpoints that go on and off the network will be protected as soon as they join, and with remote backup, remote workers are protected even outside of the office. See Optimizing Retrospect’s Algorithm for Resource Scheduling for a technical deep dive.
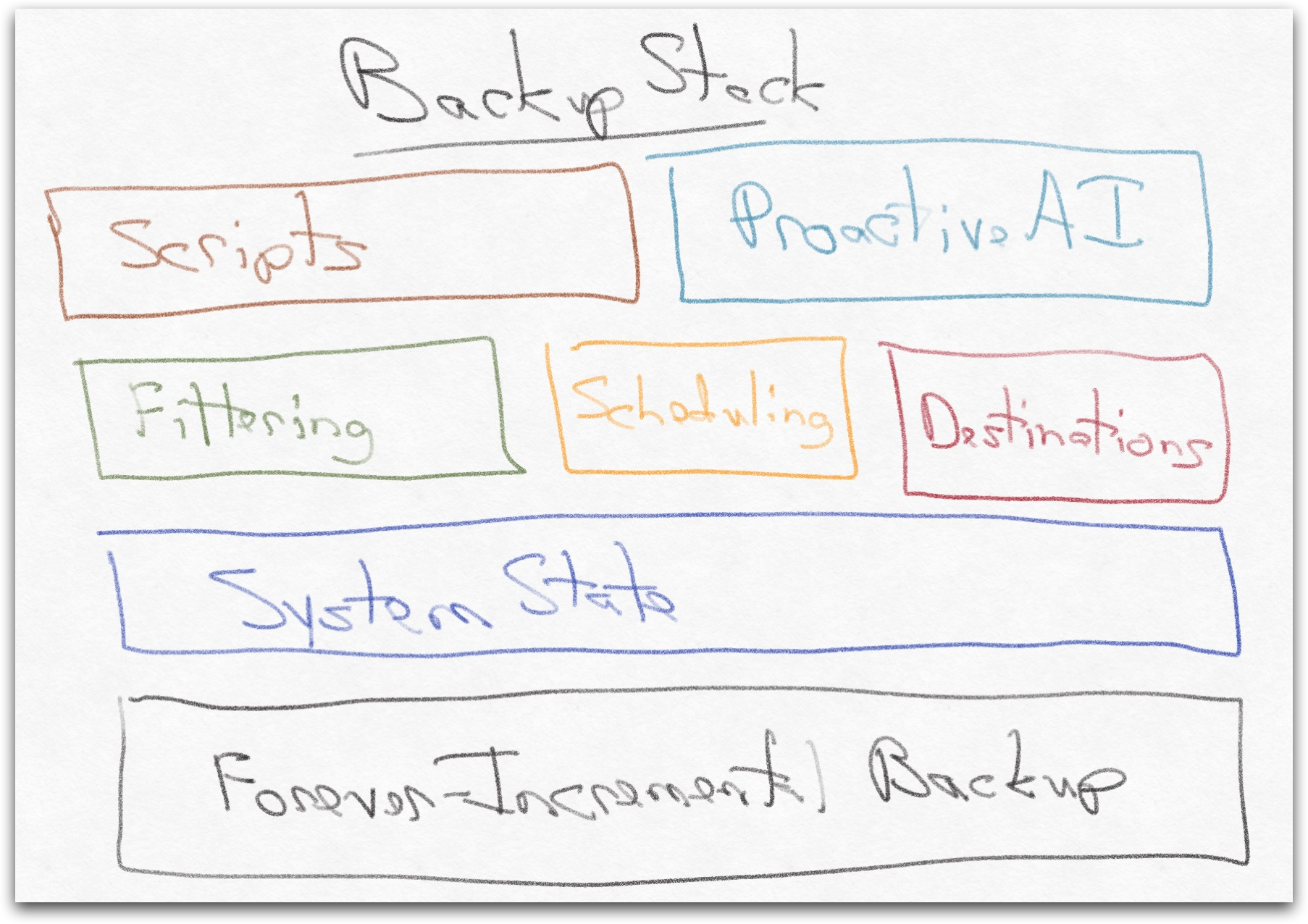
The combination and deep integration of all of these components form Retrospect’s backup stack and provide businesses with a flexible backup solution that extends to all major operating systems and includes application-level backup for Microsoft Exchange and Microsoft SQL Server. Customers can deploy Retrospect wherever it makes the most sense: on a VM, in the cloud, or on an old desktop.
Image-Based Backup Comparison
An alternative backup method is image-based backup. Image-based backup uses the blocks of data on a volume to read and protect data at a system level.
Many enterprise data protection solutions use this approach. They focus on the entire volume, copying all used blocks on a volume for a full backup and then subsequent changed blocks for incremental backups. This approach allows customers to restore entire systems, but it loses the file-level granularity of file-based backup.
To allow better flexibility, a number of solutions also support file-level restore. This granular recovery lets businesses quickly choose a point-in-time recovery for a system, launch and attach to it, and then retrieve the individual file that they needed. This workflow enables IT administrators to quickly retrieve a lost file.
However, I don’t know of any solutions that integrate file-level restore into the original system along with the ability to leave files that are newer in that folder structure, as Retrospect can.
Customer-Centric Approach
Businesses use Retrospect’s customer-centric approach to data protection to quickly restore individual files, large folders, or entire systems with incremental-forever file-based backup, system state snapshotting, filtering, scheduling, and deep integration with destinations.