December 30 2021
Scaling Data Ingestion for a Web Application to 250 Million Requests

Retrospect Management Console is Retrospect’s hosted service where businesses can connect their instances of Retrospect Backup to aggregate, analyze, and manage their backup environments. See MVP and Iteration: How We Built a Web Application for Backup Analytics for more details about why we built it.
Stack
Here is our current stack for Retrospect Management Console:
- Web framework: Ruby-on-Rails
- Background processing: Sidekiq
- Auto-Scaling: Rails Autoscale
- Authentication: Devise Ruby gem
- Database: Postgres
- Deployment: Salesforce Heroku
- Source control: GitHub Enterprise
Data Ingestion
Data requests are like ocean waves hitting a service. Ingestion is trivial for small waves, but the larger and more frequent they get, the harder it is to finish ingesting before the next wave. The service might recover for a bit, but then it gets knocked over again with an even larger wave. And of course, you can’t see the waves, so you have no warning.
As Retrospect Management Console has grown in usage, we hit two constraints: request number and request size. There were more requests, and more requests had a lot of data, up to 11MB.
In the beginning, we didn’t know what the problem was beyond Heroku telling us that the service was down. The memory consumption was far too much, and increasing the running instances (dynos) didn’t resolve the problem.
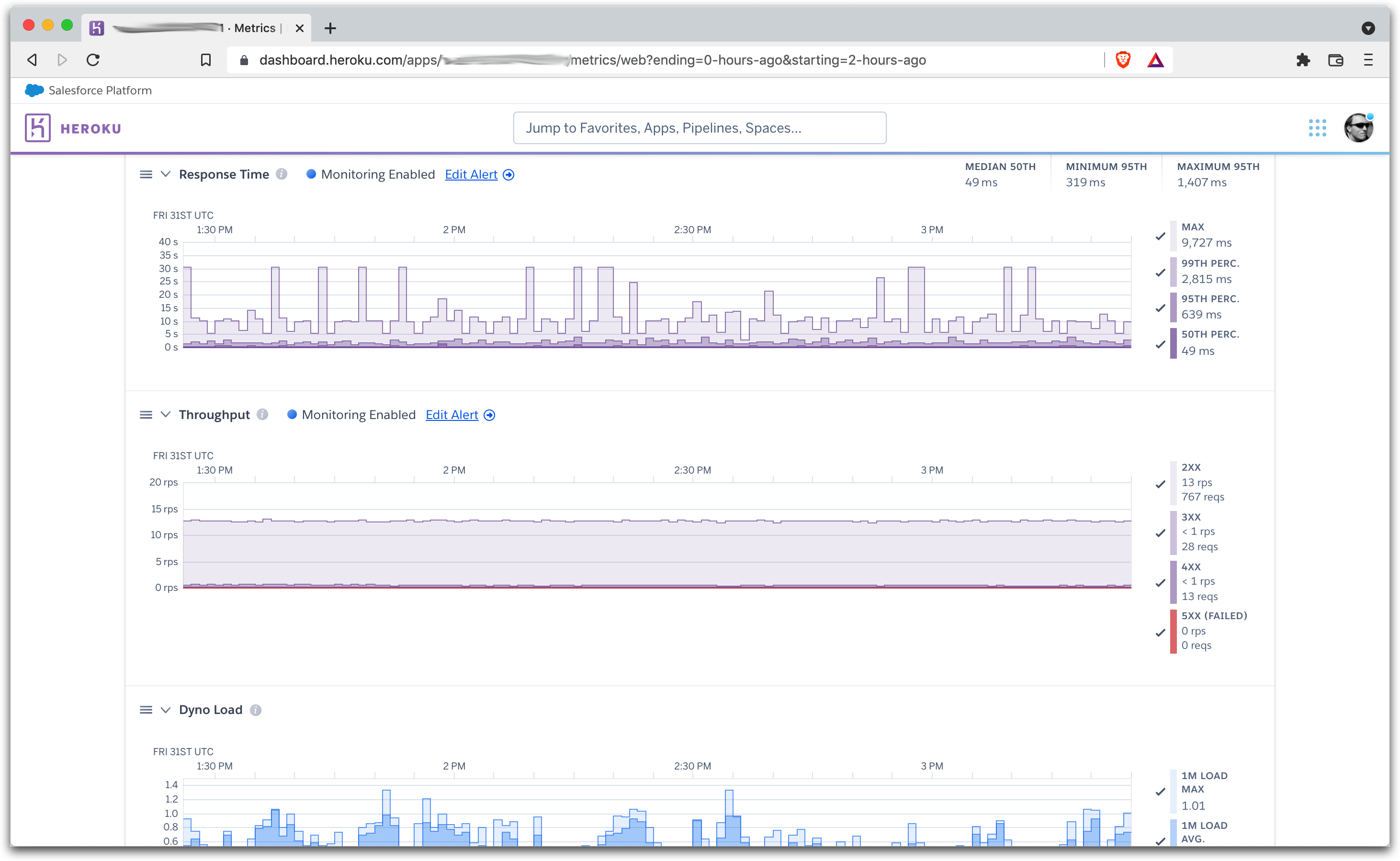
We initially focused on the memory consumption and lowered the maximum allowed amount. That ceiling temporarily resolved the 500 errors, but the service still went down with a big wave and didn’t recover without a couple manual restarts.
After investigating the problem, it was clear that our background processing framework, SuckerPunch, was the bottleneck. It ran on background Ruby threads in the same instance and was built for sending the occasional email in the background, not processing millions of large data requests every day. We had chosen it initially to ship the MVP, but it was time to move on.
We considered switching to Amazon SES or a similar cloud service, but we settled on Sidekiq. Sidekiq was created for scalable background processing in Ruby. It ran background instances and handed off jobs to them. In fact, SuckerPunch was written as a lighter version of Sidekiq, so it fit well into our existing workflow.
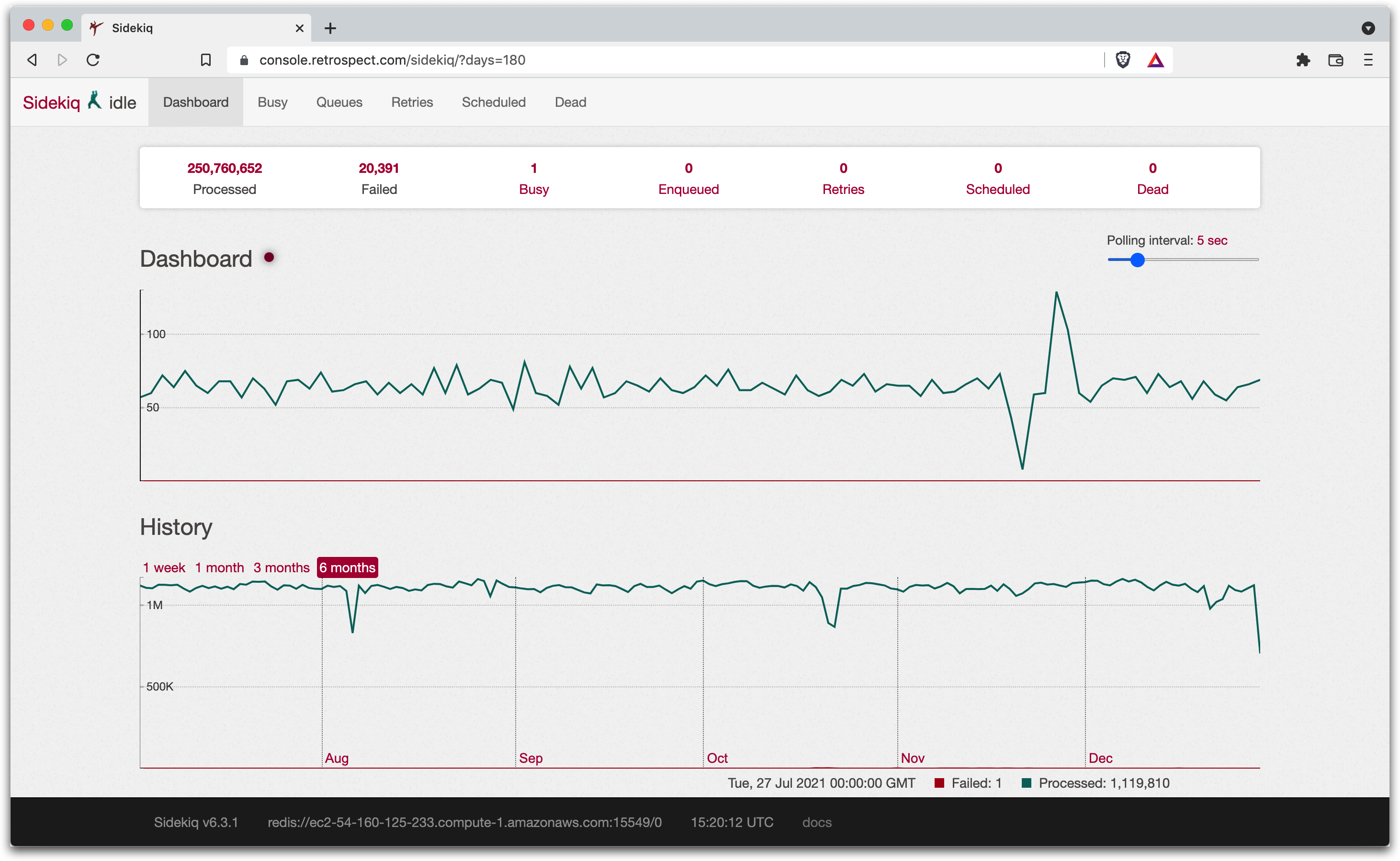
We switched to Sidekiq in April 2021. The transition was five lines of code, and it immediately resolved our scaling issues in both directions. Since then, the background instances have processed 250 million requests at 1.1 million requests per day, including 20MB requests. 20MB is a lot of JSON backup data. The service has been able to handle 300 requests per second.
Auto-Scaling
In addition to Sidekiq, we needed to automatically scale our web instances and worker instances up and down based on the amount of traffic coming in. If we underprovisioned, we would not be able to process the amount of data coming in. If we overprovisioned, we would be paying too much for the amount of data we needed to process.
Heroku offers a services for web instances, but to cover both types, we chose Rails Autoscale. Rails Autoscale automatically scales instances based on queue time for requests, and it has a number of options for scaling up and scaling down along with limiting the minimum and maximum number of instances.
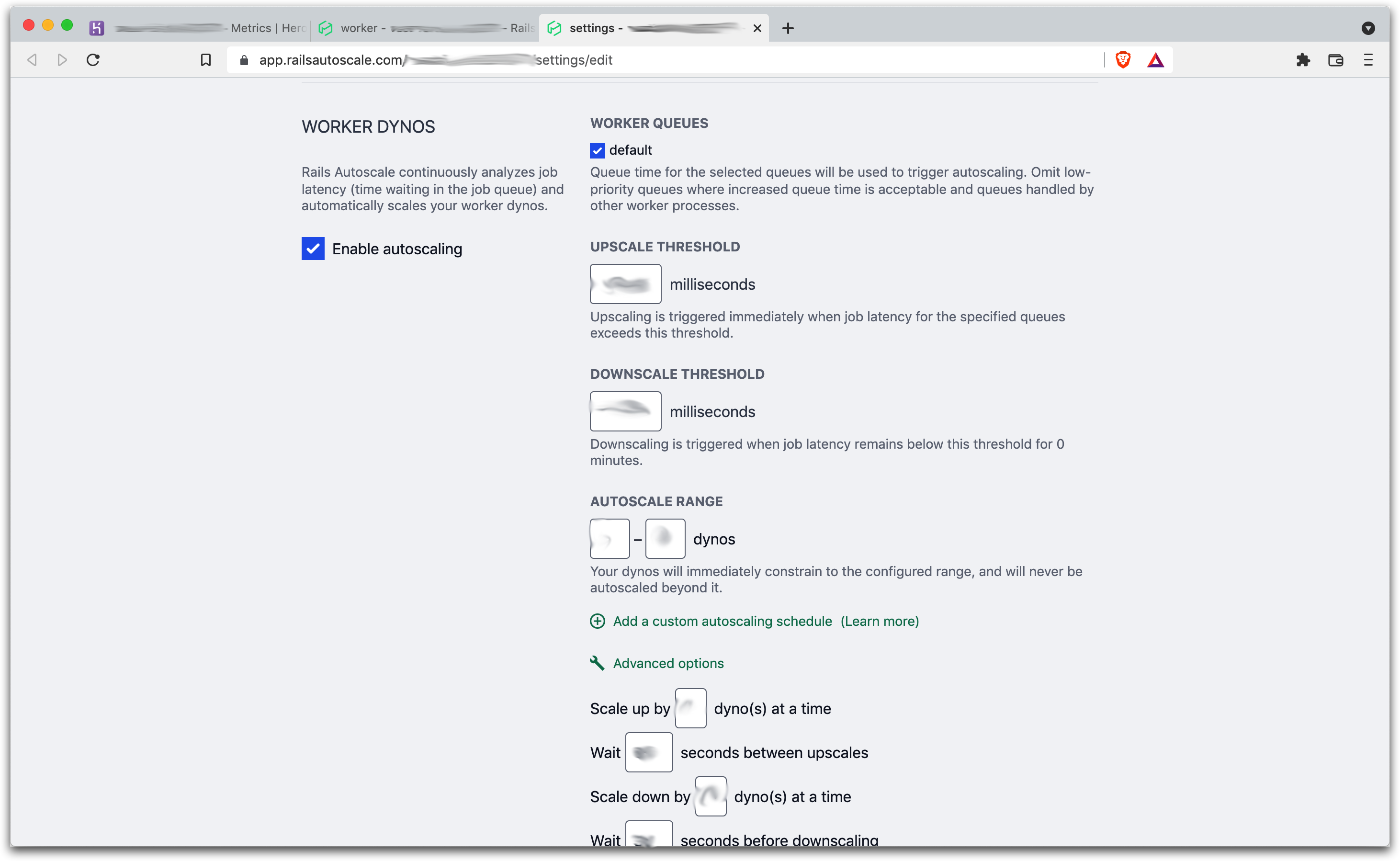
It also has a nice usage page to show how much money it’s saving you by not overprovisioning.
250 Million Requests
We’ve been thrilled by how Retrospect Management Console has grown from a product idea to solve customer problems into a shipping product that has handled 250 million requests since the summer. By monitoring the service and investigating each bottleneck in turn, the service has been able to scale up to meet customer needs, using excellent solutions like Sidekiq and Rails Autoscale.