May 31 2025
How Faster Compute, More Data, and Better Algorithms Scaled AI to ChatGPT

I heard someone comment that NeuroIPS (a computational neuroscience conference) has grown in interest and narrowed in focus over the last two decades, where there were 500 people in 2003 discussing many different AI fields, 1,500 people in 2013 focused on machine learning, and 15,000 people in 2023 only talking about Transformers.
Why? The Transformer neural network architecture scales results in terms of compute, data, and parameters. There are now 2-trillion parameter LLMs trained on 30-trillion token data sets and running on thousands of GPUs. Billions of people now use LLMs in Google Search’s AI Overview and OpenAI’s ChatGPT.
Let’s walk through the three fundamental forces that have pushed the field forward at such a fast pace: faster compute, more data, and better algorithms.
Faster Compute
LLMs don’t run on CPUs. They run on GPUs. In Building a 10-Million Parameter LLM with 300 Lines of Python and Training It in 10 Minutes, I tried running a 800k-parameter LLM on a CPU and a GPU: the GPU was 118x faster (2 hours vs 1 minute). CPUs are designed for serial execution of any set of instructions; they can handle running an OS, writing a Word document, and resizing a photo. GPUs are designed for parallelized execution of a specific set of instructions: math, specifically for graphics. It’s even in the name. GPU stands for Graphics Processing Unit, as they were originally designed for computer games.
CPUs have a small number of processing cores (8-core or even 64-core), but GPUs have thousands of cores. The Nvidia GeForce RTX 4090 ($1,600 MSRP) has 16,384 cores on a single card. Nvidia wrote a huge software framework called CUDA to abstract away the low-level details of all those cores, so that game developers could write simpler high-level software to leverage them in parallel.
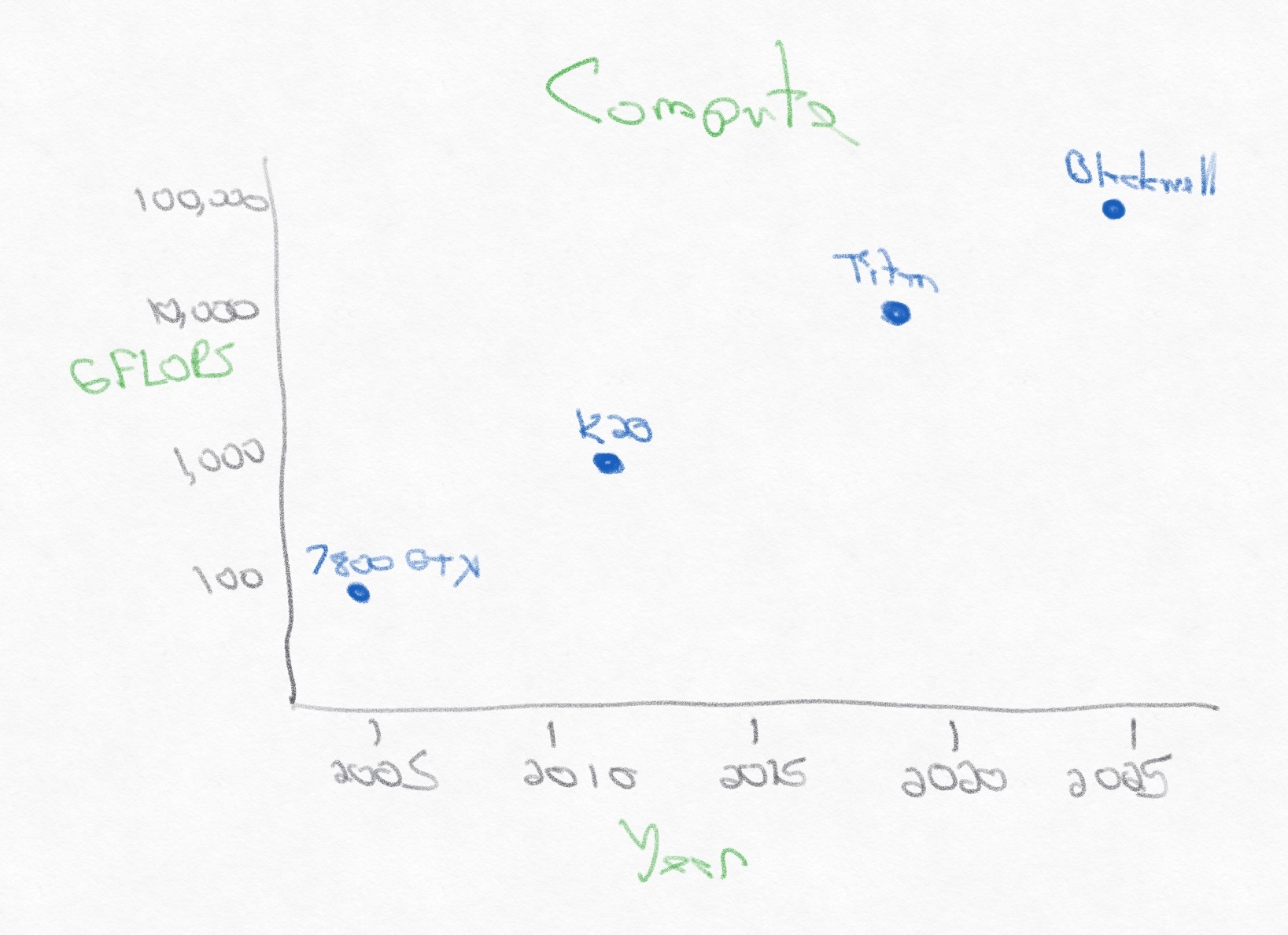
Moreover, the amount of compute per card has been growing incredibly fast. Over the last twenty years, the compute power of a single GPU card has grown 1000x from 10^2 GFLOPS to 10^5 GFLOPS. FLOPS stands for floating-point operations per second. GFLOP stands for Giga-FLOPS or 1000x. The latest GPU cards clocks in at 100 TFLOPS.
It’s purely coincidental that neural networks, like computer graphics, also require processing massive amounts of math that can be parallelized, but GPUs are a fantastic fit for neural networks. Fundamentally, GPUs are so much faster than CPUs at machine learning specifically because they are designed for solving that specific numerical problem incredibly efficiently, processing math computation over thousands of cores in parallel.
Tools such as Pytorch abstract away CUDA and tailor the experience to neural network programming. With Pytorch, developers can simply assign models to “the GPU”, without any lower-level understanding of blocks, threads, or cores. In fact, I built a 10-million parameter LLM in the post linked above by training and running inference on a single GPU.
However, a 2-trillion parameter model does not train or run on “the GPU”. Pytorch isn’t magic and reinforces the lesson that LLMs are a leaky abstraction at scale. To train a model that requires thousands of individuals GPUs, the model needs to be split up using parallelism, referred to as 3D parallelism (as there are three independent axes):
- Data Parallelism (DP): Data is split into batches. Parameter sharding is a memory optimization on top of this with tools like ZeRO (Zero Redundancy Optimizer) and FSDP (Fully Sharded Data Parallel). This is for training or high-volume inference.
- Tensor Parallelism (TP): Tensors are split within a single layer.
- Pipeline Parallelism (PP): The pipeline between layers is split.
Meta said that pre-training Llama 4 Behemoth (the 2T-parameter model) required 32,000 GPUs, but let’s focus on the simpler task of running the model. Llama 4 Behemoth might be a 2T-parameter model, but it uses Mixture-of-Experts (see “Better Algorithms”) and so only has 288B active parameters.
In practice, running the model might use an architecture like this using Nvidia 80GB H100s: 1 DP x 2 PP x 8 TP or 16 GPUs. That setup enables two axes of parallelism: splitting the model across layers for pipeline parallelism and then splitting within the individual layers for tensor parallelism. In fact, for a single request, pipeline parallelism is used simply to fit the model into GPU memory; when there are multiple requests, pipeline parallelism enables micro-batching to fully utilize the GPUs as each request progresses through the model layers.
Combining all of these axes of parallelism enables LLMs to train and run quickly and efficiently at scale, but keep in mind that this entire description is all to generate a single token. After that token is generated, it’s appended to the context window, and the entire process runs again. That workflow cannot run in parallel because those steps are dependent. Similar to most at-scale cloud services, the actual infrastructure that undergirds being able to use ChatGPT is incredibly complicated.
At a much higher level, we can look at how increasing amounts of compute has decreased the costs of generating tokens.
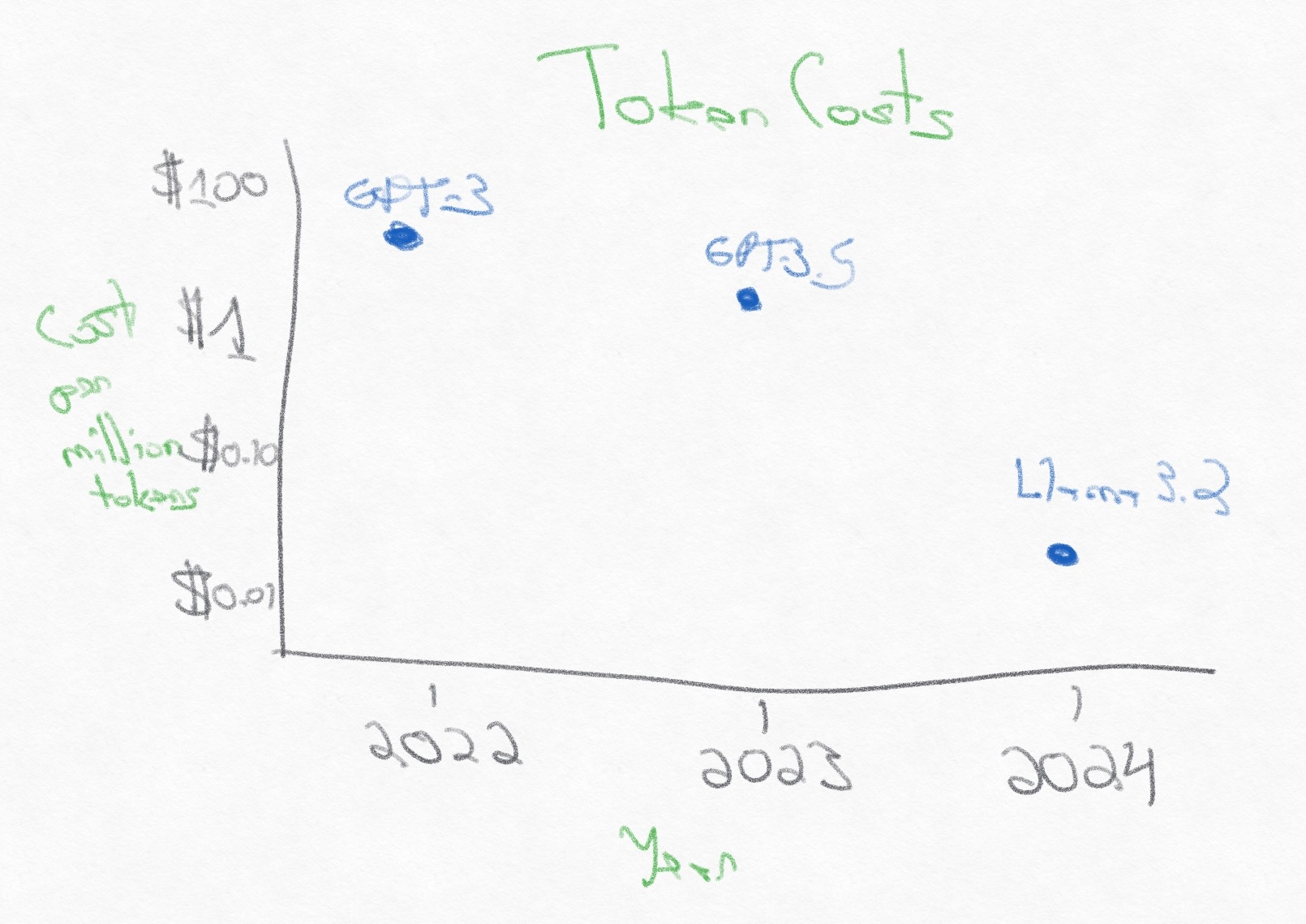
Token costs have plummeted by 100x over the last two years, from $60/million tokens for GPT-3 to $0.06/million tokens for Llama 3.2. Faster compute is making this massive amount of numerical computation far cheaper.
More Data
As compute becomes cheaper, there is an accelerating need for high-quality training data. There are training data sets for vision, speech, and other modalities, but let’s focus on text and see how training data sets have grown over just the last eight years.
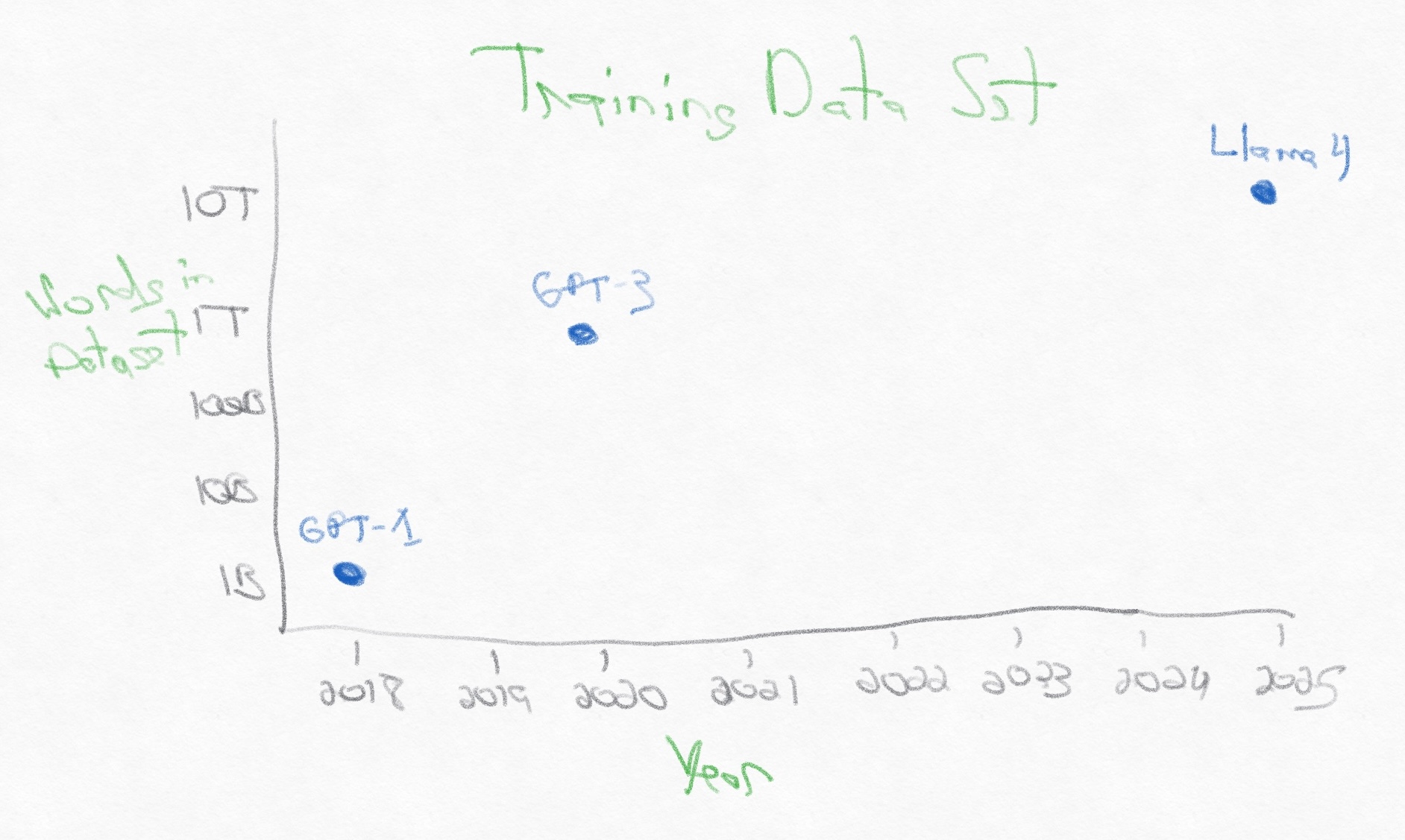
Since 2018, the training size for large language models has grown 20,000x. GPT-1 was trained on 1B words. Wikipedia has 55 million articles across all languages, comprising 29 billion words, and Llama 4 was trained on almost 1,000x more data, including text, image, and video datasets.
Better Algorithms
Faster compute is great. More data is great. It doesn’t matter if the algorithm–the neural network model–cannot embed the nuance of the data. That’s where Transformers come in. The Transformer architecture drastically increased the number of parameters for neural networks but enabled them to store far more nuance in a parallelizable data flow. More recently, Mixture-of-Experts (MoE) networks further pushed the number of parameters but, similarly, increased the accuracy of the model while keeping the number of “active” parameters at a lower number.
Let’s walk through how quickly deep learning neural network models have grown in terms of parameter count.
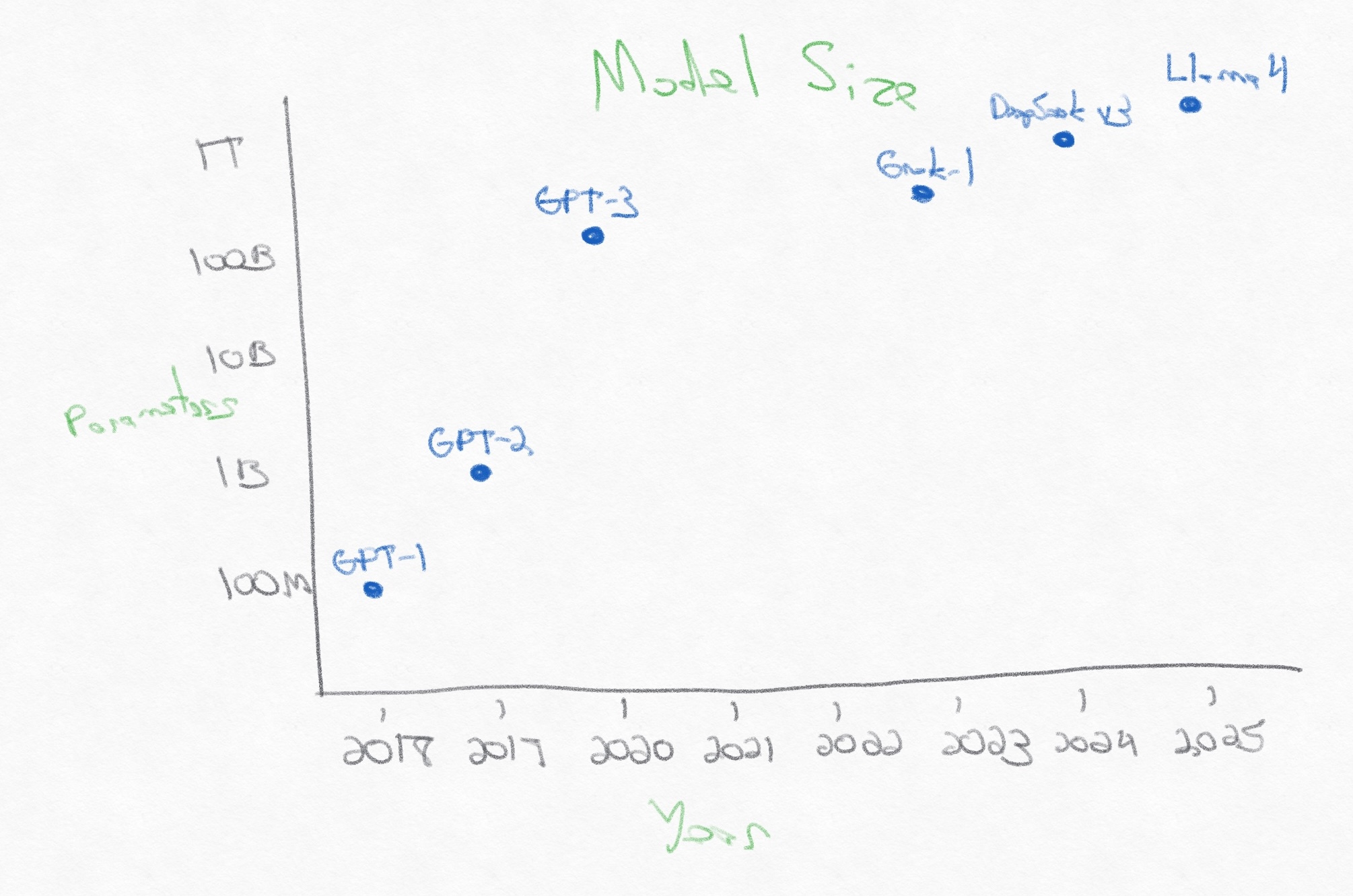
That’s a 20,000x increase in parameters in eight years. For every parameter in GPT-1, there are 20,000 more in Llama 4, and every one of those parameters can learn a little bit more about the data.
The Bitter Lesson
Every graph above is log scale.
The three dimensions driving the current wave of AI are all increasing exponentially. The pace of change feels so blisteringly fast these days precisely because all three drivers are advancing so quickly. We keep shipping faster compute. We keep expanding the data sets to train AI on. We keep improving the algorithms to train. Progress on any one of these would push AI forward. Our current exponential progress on all three made ChatGPT a reality.
In fact, there are a growing number of examples, from Google’s AlphaZero to DeepSeek’s r1, where compute and search (self-play or reinforcement learning) scale results better than any human-derived heuristic systems that researchers can come up with. Better algorithms, such as Transformers and Mixture-of-Experts, that leverage faster compute and more data continue to produce increasingly accurate results.
Greg Sutton wrote an influential essay in 2019 titled “The Bitter Lesson”, arguing that the best way forward for AI is leveraging compute and search:
“The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin…One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great. The two methods that seem to scale arbitrarily in this way are search and learning.”