October 29 2022
Adopting a Continuous Delivery (CD) Jenkins DevOps Pipeline

More than a decade ago, Retrospect Engineering set up a daily build system for our Windows and Mac products. Once a day, a cronjob would kick off a task to build the latest version of our codebase and email the results to the team. The daily build process was a fantastic method for adding automation to the build process for having a repeatable build process, ensuring the main codebase compiled in production, and storing builds that we could use to narrow down any issue that arose during regression testing.
Since then, continuous integration (CI) workflows have become a common practice for Engineering teams. Continuous integration (CI) and continuous delivery (CD) are both processes to automate building, testing, and in the case of delivery, packaging and deploying a product to the final platform for customers. This DevOps automation creates a pipeline from codebase to customers, eliminating human bottlenecks and manual steps to increase the efficiency and performance of an engineering team.
Google’s DevOps Research and Assessment (DORA) group studied thousands of teams to understand the practices and metrics for high-performing teams vs low-performing teams, and continuous delivery is a fundamental building block for high-performing teams. By relying on an automation pipeline, engineering teams can ship more features faster and better tested while reducing burnout.
Recently, we decided it was time to upgrade our infrastructure to a continuous delivery workflow to improve our efficiency as an Engineering team. Let’s walk through the original homegrown build system, what our overall goals for automation were, and how we extended the homegrown build system into a continuous delivery pipeline with Jenkins to improve our delivery performance.
Homegrown Build System
Since the mid-2000s, Retrospect has had a daily build system for Windows and Mac and a manual build for Linux.
On Windows, we’ve used Visual Build Pro to generate builds. Visual Build Pro checked out the source code from GitHub Enterprise, compiled the appropriate project, posted the build output to a NAS share, and emailed the Engineering team with the results. When we added automated testing, we updated Visual Build Pro to kick that off as well.
On Mac, we wrote our own build system. The first version was a shell script, run daily as a cron job. That lasted a couple years until we rewrote it in Ruby. The Ruby version has endured quite well. In the intervening years, we’ve added support for building different versions of the Mac application, running regressions with our automated test framework, signing them, notarizing them, and uploading the final artifacts to Amazon S3. The Ruby build script is an end-to-end build process for our Mac product.
On Linux, we have never made changes to the client agent frequently enough to justify automating the build process. We built it manually for every change.
Continuous Delivery Goals
Our homegrown system had elements of continuous integration, but there were many manual steps. Let’s walk through what we needed from a continuous delivery pipeline:
- Continuous Delivery: We wanted a single system that supported an end-to-end pipeline, starting when a pull request was merged, building, testing, packaging, deploying to Amazon S3 for download by customers, and notifying the Engineering team of the results.
- On-Premise: We use GitHub Enterprise, so we needed a system that could run on-premise and control the local testing infrastructure.
- Cross Platform: Retrospect has Windows, Mac, and Linux elements to build as well as cross-platform dependencies. We need to build a Mac artifact and then transfer it to Windows and vice versa. Moreover, we needed to check out our codebase at a single consistent point across platforms.
- Build Commit with Status: As a team, we are accustomed to having a build commit to master/main on GitHub that identifies the exact bits that were compiled and shipped, and the build commits keep version numbers and cross-platform artifacts up-to-date within the codebase. We wanted to consolidate the two commits that we currently had into a single commit and mark it with a status from the CD pipeline.
Our goal was to leverage our current build processes, knit them together into a single build pipeline, and extend that into continuous delivery.
Third-Party Build Pipeline
Building a homegrown system has the fantastic advantage of doing exactly what it was coded for and the unfortunate downside of doing nothing else. The internal team pushes the functionality forward. We needed to leverage a third-party solution to achieve our CD goals with minimal commitment.
We looked at Jenkins, GoCD, Bamboo, CircleCI, and GitHub Actions; Jenkins was open source, worked on-premise, and seemed to be popular enough that we could google for help. Jenkins was designed to be a CI system with a plugin architecture, and it had thousands of plugins. We thought it made sense to try it first.
Overall, the setup process took about three weeks of one engineer’s time, spread out over three month. We have nine stages in our pipeline using three nodes (2 Windows, 1 Mac) to perform the following steps through a versioned Groovy script.
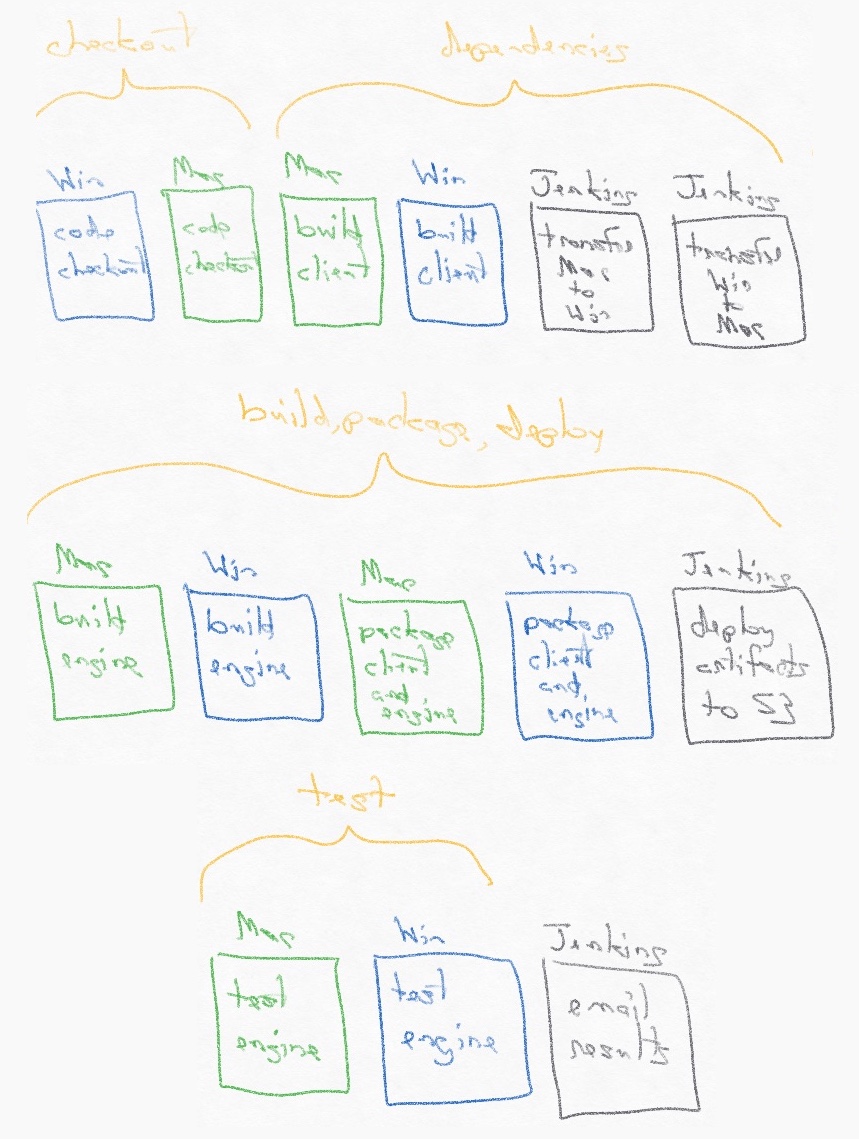
- Auto Trigger: We wanted the new system to start a new build when someone merged a pull request to master. As we use GitHub, its Webhooks were the natural choice. We originally set up GitHub Webhooks to only send Jenkins data on pull request changes, but because it didn’t actually include the master commit, Jenkins didn’t trigger the build. We had to send the push event from GitHub for Jenkins Git plugin to notify our pipeline. However, because the pipeline was triggered by pushes, the later build commit auto-triggered a new build, creating a feedback loop. We had to add special code to detect and suppress builds based on the build commit.
- Delay: We set a 30-minute delay before the pipeline starts in case an engineer merges several pull requests in quick succession (which did happen to us in practice).
- Code Checkout: We have two platforms that we’re building on, and we needed the codebase to be in the same state on both to avoid the race condition of building different commits on different platforms. We reduced this race condition from 45 minutes to 15 seconds by separating out the checkout stages and moving them to the beginning. We did experiment with checking out a specific Git hash, but that approach ran into issues when we tried to push a new build commit back to master.
- Build Dependencies: Retrospect for Windows includes a Mac binary and vice versa. The build pipeline needed to build the dependencies on both platforms and then copy them to the other platform via an Amazon S3 artifact staging folder.
- Commit Version and Dependencies: The team was accustomed to the version of the product and the above dependencies that they use in development being updated by the build system. In the past, we had the separate build systems commit these, but that approach would re-introduce the race condition from above. If one platform committed to master, the other platform would need to fetch that change or its push would fail, but because it was fetching a change, it could fetch too much. Either build commit push would fail if someone had merged another pull request, but we were trying to avoid silent bugs, rather than the build process failing. We consolidated the two platform commits into one by transferring all of the updated files from Windows onto Mac via the S3 artifact staging folder and then committing all of them.
- Build Applications: Each platform node would build Retrospect client agent and engine application as before, using the previous build systems.
- Package Applications: Jenkins was quite handy for creating the folder structure and moving files around for packaging. On Mac, we did need to code sign and notarize the binaries. These steps used to be manual, and the team really appreciated automating them.
- Deploy Applications: Our deployment process is quite straight-forward: upload them to S3 and mark as public.
- Test Applications: On Mac, the original build system continued to run automated testing on the finalized product. On Windows, Jenkins downloaded the finished binaries to a new node where it built the test framework and then ran it against the new binaries. Our tests are quite extensive, as we make backup software, so the tests actually extended the build pipeline from two hours to nine hours.
- Email Team: Jenkins sent an email at the end with the status of the build and linked (if successful) to the staged final products.
It’s a long list, but it ticks off all of our requirements. Jenkins provides us with an infrastructure for managing multiple build systems on different platforms as nodes in a single pipeline, and its Groovy script support enables us to knit those build systems together into a DevOps process.
The resulting Groovy script is 500 lines, and that count excludes the 2k-line Ruby file for building Mac and the extensive Visual Build Pro script on Windows. The option to pull the Groovy script from source code (GitHub Enterprise in our case) highlights the DevOps mindset of repeatability and automation.
While the team is really happy that Jenkins is working now, the setup process was not smooth. It took a significant amount of time to understand what Jenkins could provide us, how to connect what we needed into what it could deliver, and then codify that process in Groovy. Beyond that expertise barrier, Jenkins has bugs, like all software. We hit a number of issues where we eventually found open JIRA issues without resolution, so we worked around them.
High-Performing Team
CI/CD workflows are a necessary part of a high-performing Engineering team. While we had a good system for building and testing the software, we were missing the full continuous delivery pipeline. Like all Engineering projects, there was an opportunity cost associated with the infrastructure upgrade, but resolving this technical debt allows the teamn to focus on features rather than manual processes.
Thanks to the engineer who took on this project and overcame the hurdles we found in Jenkins to wrap up this project and to the entire team for helping out when needed! Moving to cross-platform continuous integration and continuous delivery had been a goal for years, so a huge shout-out to the Retrospect Engineering team for ticking it off this summer.